

PostgreSQL中的pg_stat


pg_stat(包括pg_stat_xx)这一系列视图及其功能,在官方手册里都被划归在Postgresql统计收集器下面,用于收集信息和报告服务器的活跃性。各个视图的具体作用可以主要参照官方手册中的相应介绍
下述的分析内容皆为pg9.2版本源码
整体分析
pg_stat作为PostgreSQL数据库的状态统计和信息收集的作用,其触发点有多处:
- autovacuum launcher process
- stats collector process
- 手动vacuum和analyze
其中手动执行vacuum、analyze与自动执行并无太大的区别,因为代码的主体逻辑相同,所以略过
autovacuum
功能
这个进程的主要作用是自动执行VACUUM和ANALYZE命令,其中ANALYZE是执行分析操作,VACUUM是进行清理操作。其对应的代码位置为/src/backend/postmaster/autovacuum.c/,在数据库整体配置中,vacuum相应的配置项在postgresql.conf文件中(搜索vacuum关键字有大量配置项)。同时需要注意的是,autovacuum是基于行级别的,所以除非在postgresql.conf文件中把track_counts设置为true,无法使用autovacuum守护进程。
触发条件
查看源码可以看到自动收集的公式为:
*threshold = vac_base_thresh + vac_scale_factor * reltuples //对应下方的(xx)thresh变量
reltuples = classForm->reltuples;//pg_class表中记录的某张表的数据行数
vacthresh = (float4) vac_base_thresh + vac_scale_factor * reltuples;
anlthresh = (float4) anl_base_thresh + anl_scale_factor * reltuples;
vactuples = tabentry->n_dead_tuples;//需要清理(被标记删除)的行数
*dovacuum = force_vacuum || (vactuples > vacthresh);
*doanalyze = (anltuples > anlthresh);
其中,reltuples为pg_class.reltuples,可以通过pg_class查询得到,例如(pg_class的数据更新同样来源于analyze,如果该数据不自动更新,可以手动analyze):
test=# select relname, reltuples from pg_class where relname = 'test';
-[ RECORD 1 ]---
relname | test
reltuples | 849
另外,可以在配置文件postgresql.conf文件中查看到相应信息为:
#autovacuum_vacuum_threshold = 50 # min number of row updates before # vacuum
#autovacuum_analyze_threshold = 50 # min number of row updates before # analyze
#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
#autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
因此可以得到:
$$vacthresh = 50 + 0.2*tuples$$
$$anlthresh = 50 + 0.1*tuples$$
那么很明显,anltuples > anlthresh会先于vactuples > vacthresh触发,也就是说,会先触发自动analyze,然后再满足一定条件后才会触发自动vacuum
举例
假如一张表有1000行记录,那么anlthresh = 50+0.1*1000 = 150,再根据doanalyze = (anltuples > anlthresh),所以改变的数据量要大于150才会做自动统计信息收集,也就是说至少删除151行数据才会触发自动收集统计信息。自动收集统计信息发生之后,vacuum对应的tuples的 数据就为1000-151=849,所以vacthresh = 50+0.2*849 = 219.8。也就是说至少删除220行数据才会触发vacuum。简单的说就是先触发自动统计信息收集,然后用剩余的行数再计算vacthresh的值从而得到最终触发vacuum的行数。
注意:这里是采用的删除操作,若是修改操作,那么表中的有效行数其实一直都是1000,而不是849等数目
stats收集进程
功能
也有人把这个进程称为pgstat进程,用于收集和报告服务器活跃性信息。例如可以给出对表和索引的访问计数、计算出函数的调用次数等,对应的统计数据可以通过pg_stat和pg_statio系统视图进行访问。这部分功能可以通过postgresql.conf中的配置项开启关闭,具体配置项含义参见官方手册
处理逻辑
pgstat进程的源码主要为/src/backend/postmaster/pgstat.c,主逻辑函数为PgstatCollectorMain,其调用关系如下:
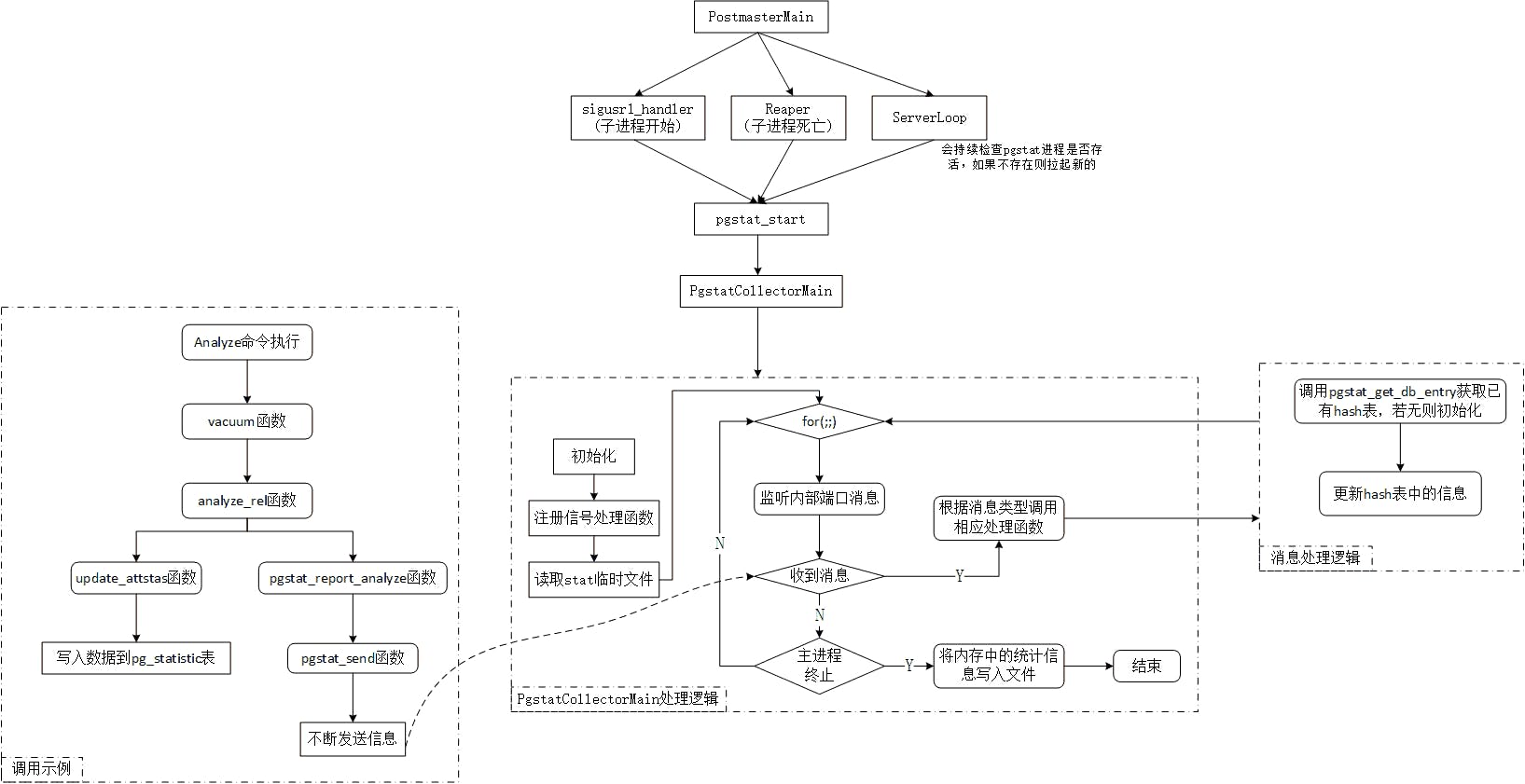
- 一旦数据库进程正常启动,PgstatCollectorMain就会进入内部消息端口的监听状态
- pgstat_read_statsfiles函数读取的是
postgresql.conf配置文件中stats_temp_directory参数所对应的目录中的临时文件(默认为pg_stat_tmp,即数据库安装路径中data/pg_stat_tmp/路径) - PgstatCollectorMain初始化时,会调用pgstat_read_statsfiles读取临时文件,构建统计信息的hash表,如果读取失败或者是第一次启动,则会把各种统计信息置为初始化状态(即计数置为0)
- 如果UDP Socket端口监听超时,将检查Postmaster状态,若Postmaster失效或者PgStat接收到退出消息(通常是指采用pg_ctl stop等命令停止数据库运行),则退出PgStat进程。在退出前要将数据库、表、函数的统计信息写入pgstat.stat文件,并删除pg_stat_tmp中的临时文件。
调试
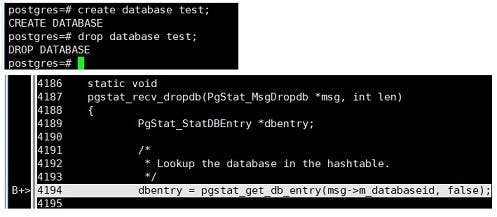
gdb调试时attach到postgres: stats collector process这个进程上。该进程一直在循环中,如果想要观察到所需的debug信息,必须在对应的处理函数中设置断点。
例如:想要观察PGSTAT_MTYPE_DROPDB的处理,设置断点在pgstat_recv_dropdb函数中,然后输入c,让程序进入pgstat信息循环接收逻辑中,接着新建一个database后再去drop,就能观察到对应的断点触发从而进入调试
各表功能
以下是对各表/视图功能的简略总结,有几个注意点:
- 这些统计表中的数据不是实时更新的,原因在于:
- 每个独立的服务进程只有在进入空闲状态时才会向ps_stat进程发送访问计数,因此正在处理的查询、事务等无法马上计入这些统计数据中;
- pg_stat进程本身至少间隔每PGSTAT_STAT_INTERVAL毫秒(默认为500)发送一次新报告
- 由track_activities收集的当前查询信息时实时更新的
- 对于事务而言,每个事务开始时会获取一个当前统计信息的快照,所以在事务执行过程中,这些统计信息不会更新。如果想要看这些统计信息发生变化,可以考虑调用pg_stat_clear_snapshot(),它会丢弃当前快照,并在下次使用统计信息时重新生成一个新的快照。不这样做的话,只能在事务外部来查看统计信息了。
| 视图名称 | 功能描述 |
| pg_stat_database | 跨DB,统计DB内的各种操作信息,如DB内提交的事务数等 |
| pg_stat_activity | 跨DB,统计进程的活动信息 |
| pg_stat_bgwriter | 跨DB,统计后端写进程的操作信息,如写入的缓冲区总量等 |
| pg_stat_replication | 跨DB,统计WAL发送进程的相关信息 |
| pg_stat_database_conflicts | 跨DB,记录由于备用服务器恢复而导致各个DB查询取消的计数 |
| pg_stats | 本身源自于系统表pg_statistic,记录了当前DB中表内各个字段的统计信息,如某个字段中非空数据的分布、数值的使用频率等。这些记录数据对于数据库的查询有一定优化作用。 |
| pg_stat_all_tables | 记录了当前DB中,对某个表的行进行操作的次数,如插入的行数、删除的行数 |
| pg_stat_sys_tables | 与pg_stat_all_tables相同,除了只显示系统表 |
| pg_stat_user_tables | 与pg_stat_all_tables相同,除了只显示系统表 |
| pg_stat_xact_all_tables | 与pg_stat_all_tables相似,不过只在事务中有效。即需要通过begin开启一个事务后,才能通过该表查看这个事务内的统计信息。如果不通过begin开启事务而直接操作表(如插入),该表的计数会保持为0而不会变化 |
| pg_stat_xact_sys_tables | 与pg_stat_xact_all_tables相同,除了只显示系统表 |
| pg_stat_xact_user_tables | 与pg_stat_xact_all_tables相同,除了只显示系统表 |
| pg_stat_all_indexes | 记录当前DB中各表的索引,以及索引的操作信息,如通过索引抓取的行数 |
| pg_stat_sys_indexes | 和pg_stat_all_indexes相同,但只显示系统表上的索引 |
| pg_stat_user_indexes | 和pg_stat_all_indexes相同,但只显示用户表上的索引 |
| pg_statio_all_indexes | 记录当前DB中各表的索引,同时包含操作索引中涉及的I/O统计,如根据索引命中的缓存、磁盘数 |
| pg_statio_sys_indexes | 和pg_statio_all_indexes一样的,但是只显示系统表上的索引 |
| pg_statio_user_indexes | 和pg_statio_all_indexes一样,但只显示用户表上的索引 |
| pg_statio_all_tables | 记录当前DB中查询表(包含TOAST表)的统计信息,如从表读取的磁盘块数 |
| pg_statio_sys_tables | 和pg_statio_all_tables一样,但只显示系统表 |
| pg_statio_user_tables | 和pg_statio_all_tables一样,但只显示用户表 |
| pg_statio_all_sequences | 记录当前DB中序列的I/O信息,如序列缓存命中数 |
| pg_statio_sys_sequences | 和pg_statio_all_sequences一样, 但只显示系统序列。因为目前没有定义系统序列,所以这个视图总是空的 |
| pg_statio_user_sequences | 和pg_statio_all_sequences一样,但只显示用户序列 |
| pg_stat_user_functions | 记录当前DB中跟踪函数的执行信息,如函数的调用次数、调用时间等 |
| pg_stat_xact_user_functions | 与pg_stat_user_functions相似,不过只在事务中有效 |
| pg_stat_archiver | 在v9.2版本中不存在,跨DB,统计WAL归档信息 |
pg_stat_activity
以该视图的分析为例,进行比较详细的说明,之后的其它视图将简略部分步骤
定义
在数据库中查看相应的视图定义,结果如下:
test=# \d+ pg_stat_activity;
View "pg_catalog.pg_stat_activity"
Column | Type | Modifiers | Storage | Description
------------------+--------------------------+-----------+----------+-------------
datid | oid | | plain |
datname | name | | plain |
pid | integer | | plain |
usesysid | oid | | plain |
usename | name | | plain |
application_name | text | | extended |
client_addr | inet | | main |
client_hostname | text | | extended |
client_port | integer | | plain |
backend_start | timestamp with time zone | | plain |
xact_start | timestamp with time zone | | plain |
query_start | timestamp with time zone | | plain |
state_change | timestamp with time zone | | plain |
waiting | boolean | | plain |
state | text | | extended |
query | text | | extended |
View definition:
SELECT s.datid, d.datname, s.pid, s.usesysid, u.rolname AS usename,
s.application_name, s.client_addr, s.client_hostname, s.client_port,
s.backend_start, s.xact_start, s.query_start, s.state_change, s.waiting,
s.state, s.query
FROM pg_database d,
pg_stat_get_activity(NULL::integer) s(datid, pid, usesysid, application_name, state, query, waiting, xact_start, query_start, backend_start, state_change, client_addr, client_hostname, client_port),
pg_authid u
WHERE s.datid = d.oid AND s.usesysid = u.oid;
可以看到该视图其实是由pg_database和函数pg_stat_get_activity生成。查看函数pg_stat_get_activity的调用关系可以知道,该函数未被其它代码引用,且为fmgrtab.c中定义的外部接口,所以每次查询pg_stat_activity都需要实时调用一次pg_stat_get_activity函数
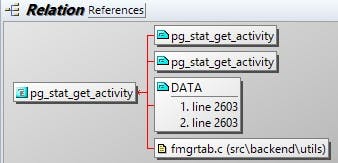
源码分析
pg_stat_get_activity代码主要被分为2个部分
初始化
以if (SRF_IS_FIRSTCALL())为划分,其整体是为了完成表结构和内存信息等的初始化,主要分为下面两步:
- 初始化表结构
tupdesc = CreateTemplateTupleDesc(14, false);
TupleDescInitEntry(tupdesc, (AttrNumber) 1, "datid",
OIDOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 2, "pid",
INT4OID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 3, "usesysid",
OIDOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 4, "application_name",
TEXTOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 5, "state",
TEXTOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 6, "query",
TEXTOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 7, "waiting",
BOOLOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 8, "act_start",
TIMESTAMPTZOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 9, "query_start",
TIMESTAMPTZOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 10, "backend_start",
TIMESTAMPTZOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 11, "state_change",
TIMESTAMPTZOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 12, "client_addr",
INETOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 13, "client_hostname",
TEXTOID, -1, 0);
TupleDescInitEntry(tupdesc, (AttrNumber) 14, "client_port",
INT4OID, -1, 0);
funcctx->tuple_desc = BlessTupleDesc(tupdesc);
- 初始化后台进程
funcctx->user_fctx = palloc0(sizeof(int));
if (PG_ARGISNULL(0))
{
/* Get all backends */
funcctx->max_calls = pgstat_fetch_stat_numbackends();
}
else
{
/*
* Get one backend - locate by pid.
*
* We lookup the backend early, so we can return zero rows if it
* doesn't exist, instead of returning a single row full of NULLs.
*/
int pid = PG_GETARG_INT32(0);
int i;
int n = pgstat_fetch_stat_numbackends();
for (i = 1; i <= n; i++)
{
PgBackendStatus *be = pgstat_fetch_stat_beentry(i);
if (be)
{
if (be->st_procpid == pid)
{
*(int *) (funcctx->user_fctx) = i;
break;
}
}
}
if (*(int *) (funcctx->user_fctx) == 0)
/* Pid not found, return zero rows */
funcctx->max_calls = 0;
else
funcctx->max_calls = 1;
}
MemoryContextSwitchTo(oldcontext);
}
查询并填充数据
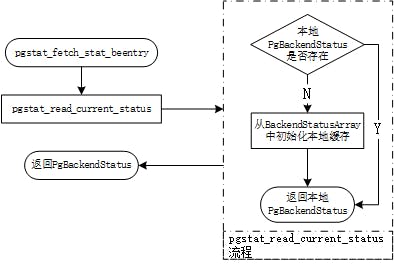
因代码太长,故不再列出,其作用就是调用函数pgstat_fetch_stat_beentry()得到后台的相关数据,然后依次填入到定义好的表字段下,最后将完整的信息返回出去。
其中,函数pgstat_fetch_stat_beentry()的处理逻辑如下:
pg_stat_database
该视图的定义如下:
SELECT d.oid AS datid, d.datname,
pg_stat_get_db_numbackends(d.oid) AS numbackends,
pg_stat_get_db_xact_commit(d.oid) AS xact_commit,
pg_stat_get_db_xact_rollback(d.oid) AS xact_rollback,
pg_stat_get_db_blocks_fetched(d.oid) - pg_stat_get_db_blocks_hit(d.oid) AS blks_read,
pg_stat_get_db_blocks_hit(d.oid) AS blks_hit,
pg_stat_get_db_tuples_returned(d.oid) AS tup_returned,
pg_stat_get_db_tuples_fetched(d.oid) AS tup_fetched,
pg_stat_get_db_tuples_inserted(d.oid) AS tup_inserted,
pg_stat_get_db_tuples_updated(d.oid) AS tup_updated,
pg_stat_get_db_tuples_deleted(d.oid) AS tup_deleted,
pg_stat_get_db_conflict_all(d.oid) AS conflicts,
pg_stat_get_db_temp_files(d.oid) AS temp_files,
pg_stat_get_db_temp_bytes(d.oid) AS temp_bytes,
pg_stat_get_db_deadlocks(d.oid) AS deadlocks,
pg_stat_get_db_blk_read_time(d.oid) AS blk_read_time,
pg_stat_get_db_blk_write_time(d.oid) AS blk_write_time,
pg_stat_get_db_stat_reset_time(d.oid) AS stats_reset
FROM pg_database d;
这些函数均位于/src/backend/utils/adt/pgstatfuncs.c/中,其功能都比较简单,不再这里详述,具体说明可以直接参考官方手册中对视图各个字段的解释来了解。这里仅以pg_stat_get_db_numbackends函数作为示例:
//获取连接到当前DB的后端数量
pg_stat_get_db_numbackends(PG_FUNCTION_ARGS)
{
Oid dbid = PG_GETARG_OID(0);
int32 result;
int tot_backends = pgstat_fetch_stat_numbackends(); //获取总的后端数量
int beid;
result = 0;
for (beid = 1; beid <= tot_backends; beid++)
{
PgBackendStatus *beentry = pgstat_fetch_stat_beentry(beid);
if (beentry && beentry->st_databaseid == dbid) //检查DB的oid是否相等,符合即证明后端连接到了当前的DB
result++;
}
PG_RETURN_INT32(result);
}
而上述的pgstat_fetch_stat_numbackends()后续也将调往pgstat_read_current_status(),与pg_stat_activity流程相似